We’ve developed networking as a way to share resources and information, and how that’s achieved directly maps to the particular architecture of the network operating system software. There are two main network types you need to know about: peer-to-peer and client-server. And by the way, it’s really tough to tell the difference just by looking at a diagram or even by checking out live video of the network humming along. But the differences between peer-to-peer and client-server architectures are pretty major. They’re not just physical; they’re logical differences. You’ll see what I mean in a bit.
Peer-to-Peer Networks
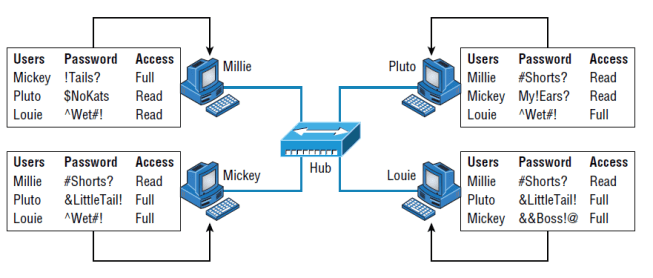
Computers connected together in peer-to-peer networks do not have any central, or special, authority—they’re all peers, meaning that when it comes to authority, they’re all equals. The authority to perform a security check for proper access rights lies with the computer that has the desired resource being requested from it.
It also means that the computers coexisting in a peer-to-peer network can be client machines that access resources and server machines and provide those resources to other computers. This actually works pretty well as long as there isn’t a huge number of users on the network, if each user backs things up locally, and if your network doesn’t require much security.
If your network is running Windows, Mac, or Unix in a local LAN workgroup, you have a peer-to-peer network. Keep in mind that peer-to-peer networks definitely present security-oriented challenges; for instance, just backing up company data can get pretty sketchy!
Since it should be clear by now that peer-to-peer networks aren’t all sunshine, backing up all your critical data may be tough, but it’s vital! Haven’t all of us forgotten where we’ve put an important file? And then there’s that glaring security issue to tangle with. Because security is not centrally governed, each and every user has to remember and maintain a list of users and passwords on each and every machine. Worse, some of those all-important passwords for the same users change on different machines—even for accessing different resources.
Client-Server Networks

Client-server networks are pretty much the polar opposite of peer-to-peer networks because in them, a single server uses a network operating system for managing the whole network. Here’s how it works: A client machine’s request for a resource goes to the main server, which responds by handling security and directing the client to the desired resource.
This happens instead of the request going directly to the machine with the desired resource, and it has some serious advantages. First, because the network is much better organized and doesn’t depend on users remembering where needed resources are, it’s a whole lot easier to find the files you need because everything is stored in one spot—on that special server. Your security also gets a lot tighter because all usernames and passwords are on that specific server, which is never ever used as a workstation. You even gain scalability—client server networks can have legions of workstations on them. And surprisingly, with all those demands, the network’s performance is actually optimized—nice!
Many of today’s networks are hopefully a healthy blend of peer-to-peer and clientserver architectures, with carefully specified servers that permit the simultaneous sharing of resources from devices running workstation operating systems. Even though the supporting machines can’t handle as many inbound connections at a time, they still run the server service reasonably well. And if this type of mixed environment is designed well, most
networks benefit greatly by having the capacity to take advantage of the positive aspects of both worlds.